―しがない農学徒の雑記帳―
しがない農学徒が日々思うところを書き散らします。項目
ポケモンの系統樹
二番煎じ感がありますが、ポケモンの系統樹を推測してみました。筆者が知る限りの一番最初は、にしむらたかひろ氏の「ポケモン系統樹かけるかな?」です。同氏は再節約法によりポケモンの系統樹を推測しましたが、筆者は近隣結合法に類似した方法で解析を行いました。つまり、覚えるわざのパターンが似ているポケモン同士をまとめて、視覚化しました。数学を勉強するとこーゆー遊びができます。
材料
初代ポケモンの最終進化形態使用ソフトウェア
エクセル (データ入力)、R (クラスタリング)、FigTree (樹状図の編集)方法
まず、どのポケモンがどのわざを覚えるのかを表にまとめました。このとき、わざマシンでしか覚えられないわざは除外しました。わざましんは遺伝子導入のようなものだと思ったからです。
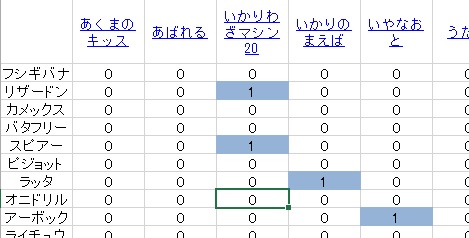
次に、ポケモン間の非類似度をもとめるために類似度をもとめました。類似度の 1 つであるピアソンの積率相関係数というものを各ポケモン間で計算します。ピアソンの積率相関係数を r とおくと, 2 ( 1 - r) は非類似度として扱えることが知られており ( http://aoki2.si.gunma-u.ac.jp/lecture/misc/clustan.html )、この非類似度を用いて計算しました。
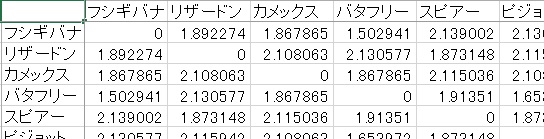
非類似度の小さいもの (似ているもの) 同士は同じまとまりに入るようにし、非類似度の高いもの同士は異なるまとまりに入るように分類します。まとまりの中は似ているようにしてまとまり間は似ていないようにします。実際の計算には Ward 法という方法を用いました。
その結果、樹状図が得られます。ミュウには特に思い入れがあるので、ミュウが外側にくるように樹状図を編集しました (データ解析という文脈では推奨されません)。というか、ミュウがポケモンの源みたいな設定があったような。。。

図: ポケモンの系統樹(linked to PDF)。
今回の手法はデータマイニングという、大量にあるデータから知識を発見する事を旨とする学問の手法を用いました。大量にあるデータを把握するのは困難なので、まずはデータを分類しましょう、という手法です。分類というのは物事を把握するのに人間が最初にする行いであり、分類は生物学の十八番で、云々。ちなみに、樹状図を じゅじょうじゅ と言ってしまう場合はデンドログラムというとかっこよくていいと思います。